FairerCLIP: Debiasing CLIP's Zero-Shot Predictions using Functions in RKHSs
Sepehr Dehdashtian*, Lan Wang*, Vishnu N. Boddeti
Michigan State University



Bias in CLIP's Zero-Shot Prediction

- Avg 88%
- Gap 15%
Types of Attribute Dependency
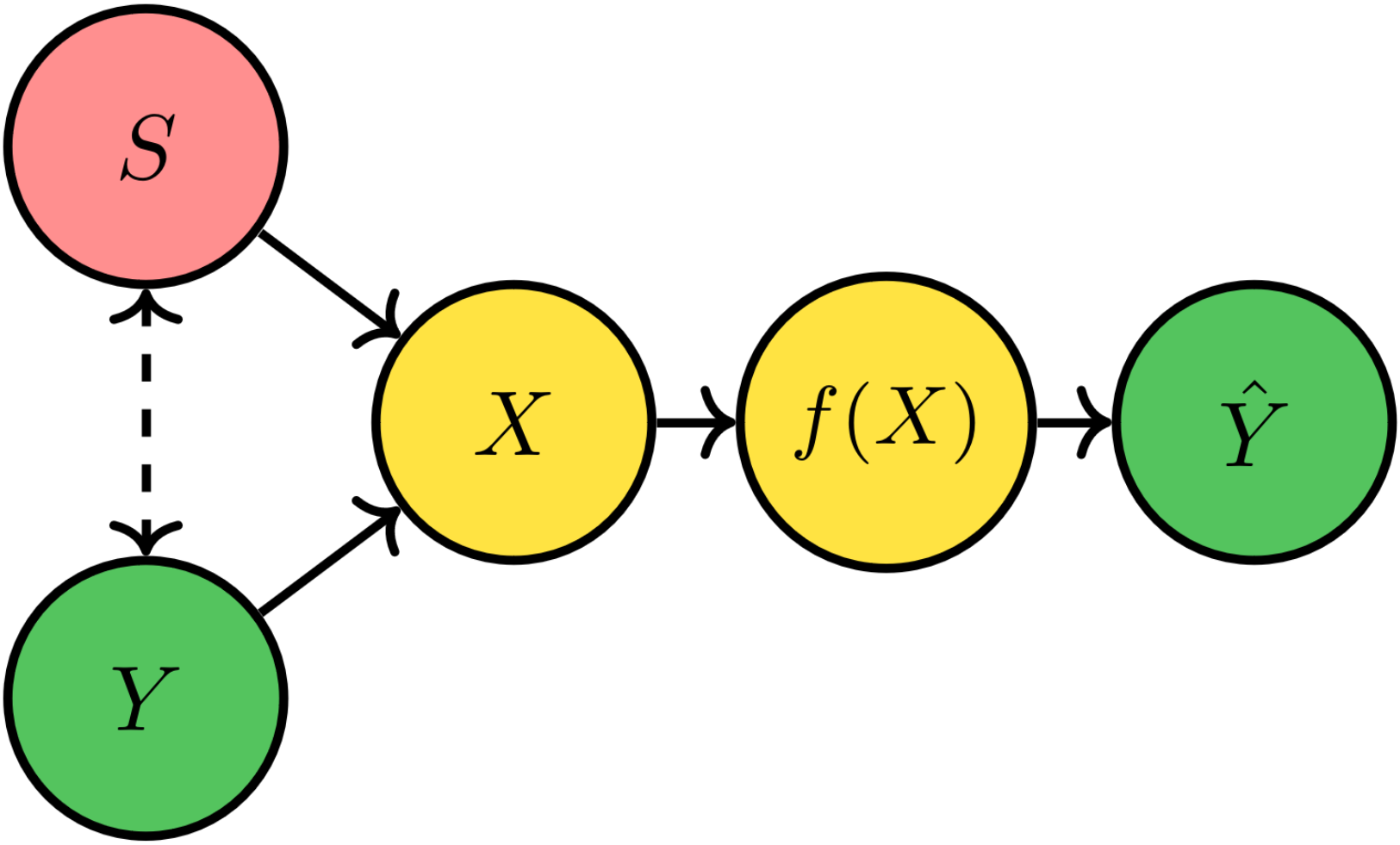
-
Y: Hair Color
-
S: Gender
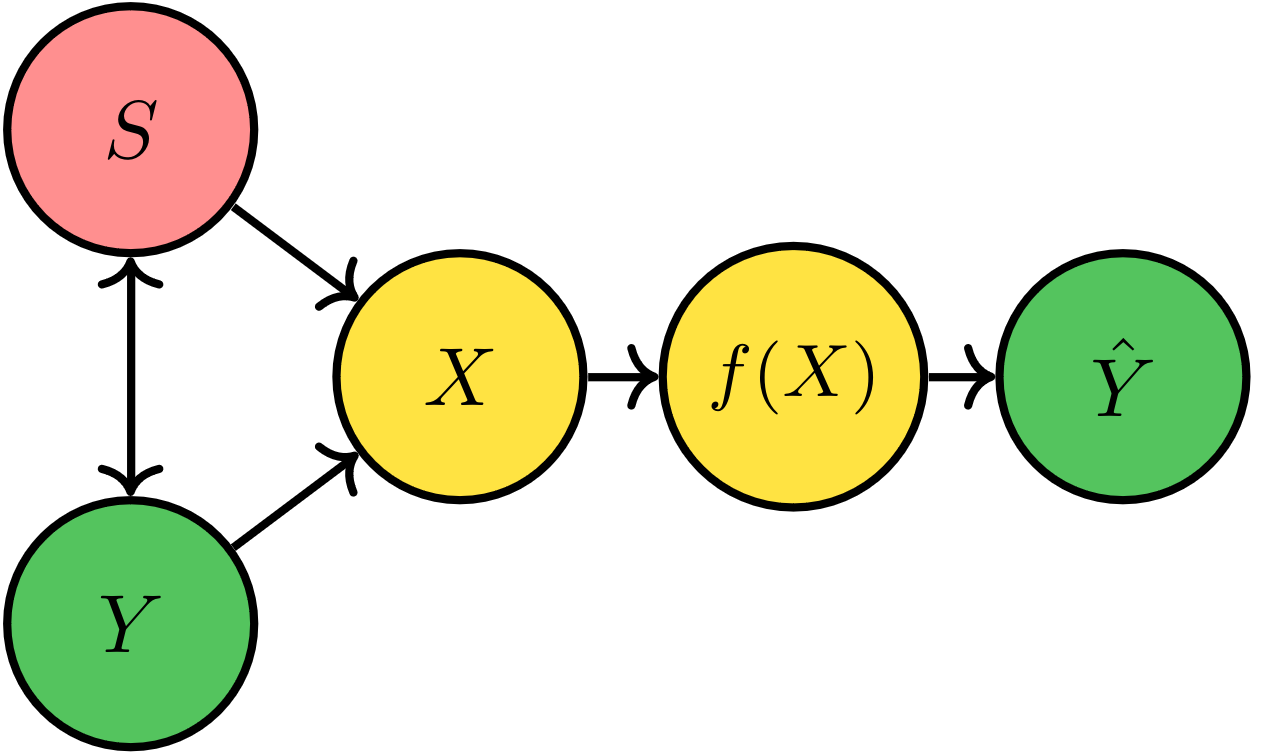
-
Y: Cheekbone Height
-
S: Gender
Drawbacks of Prior Works
- Type of correlation: Only spurious correlation.
- Need of labels: rely on GT labels.
- Efficiency: struggle in convergence.
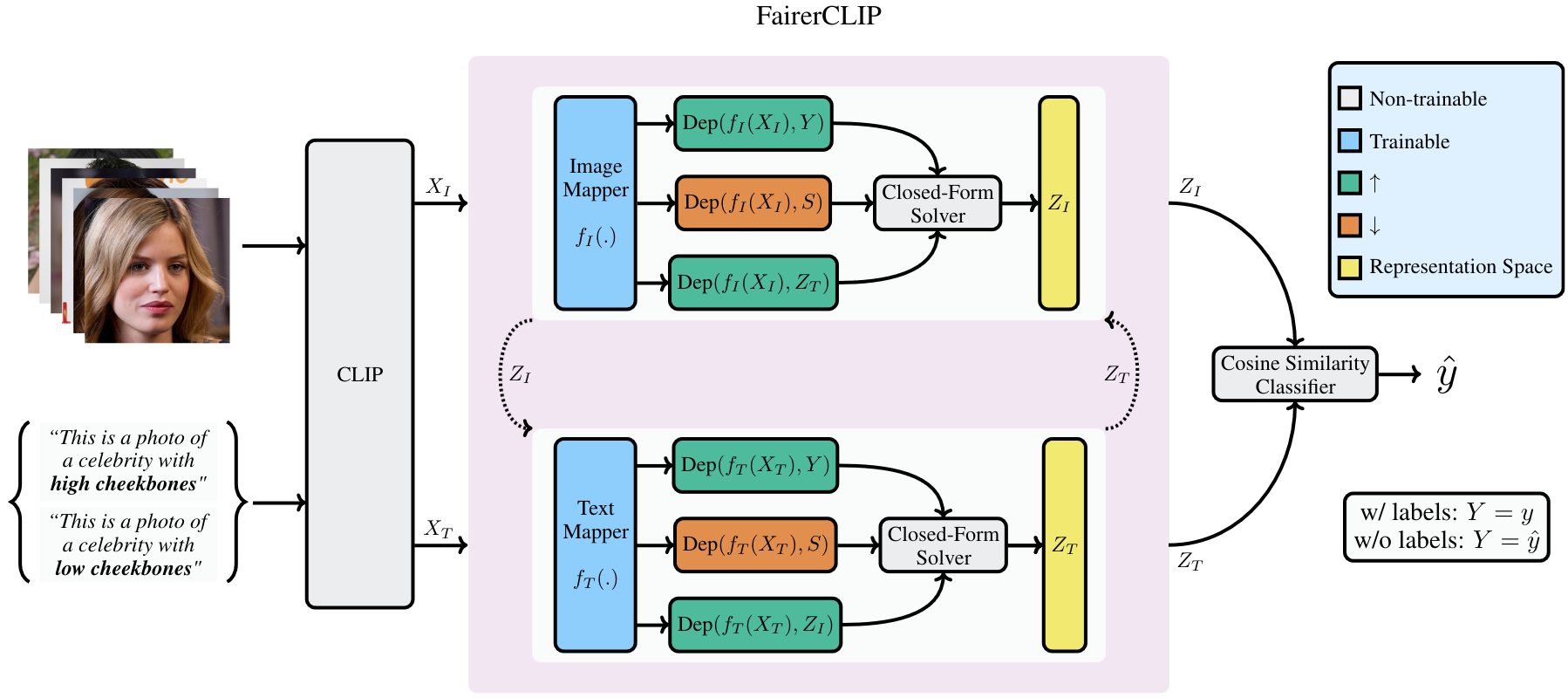
FairerCLIP
Problem Setting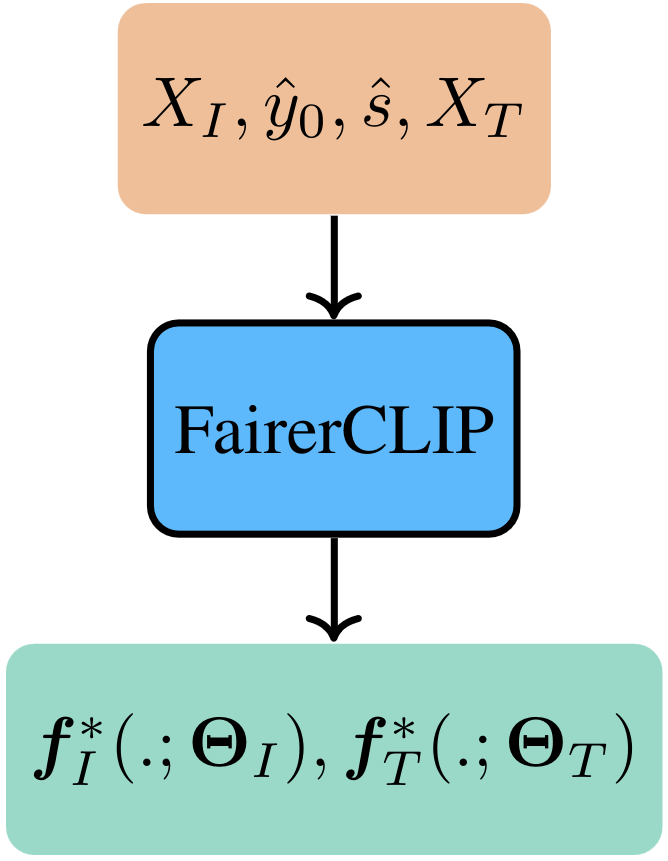
Objective Function
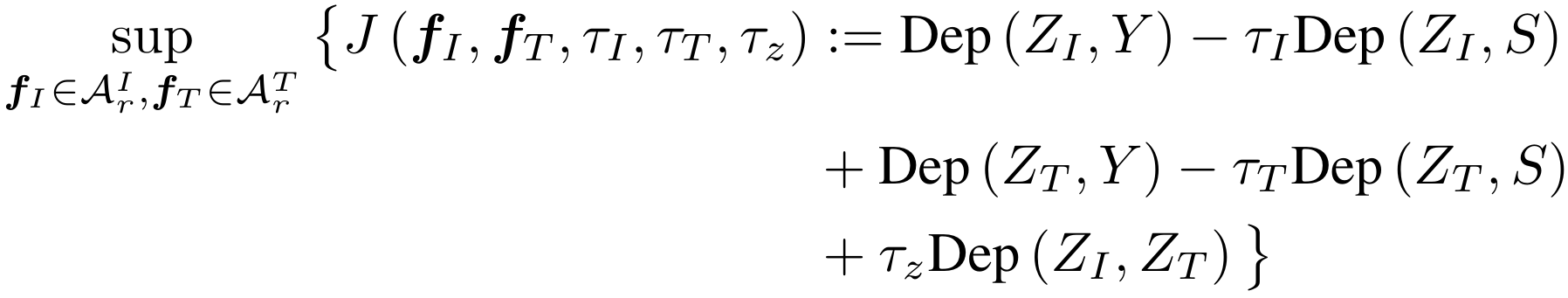
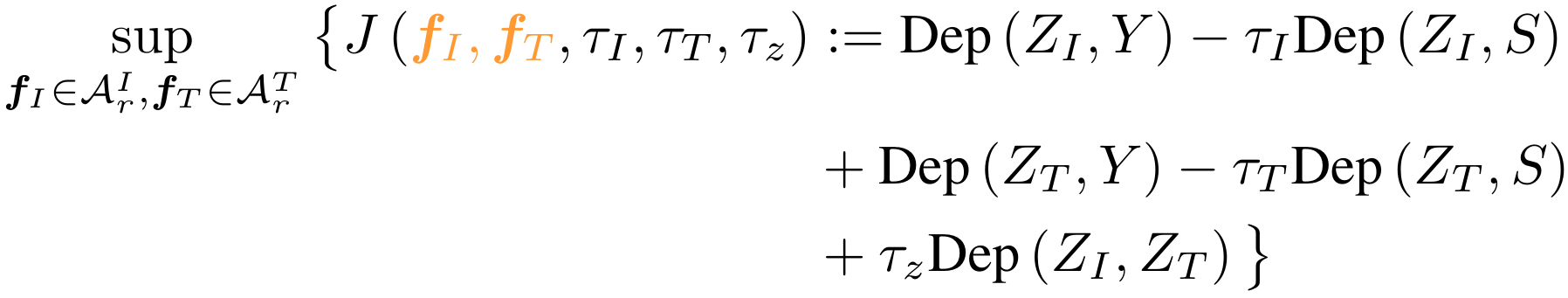
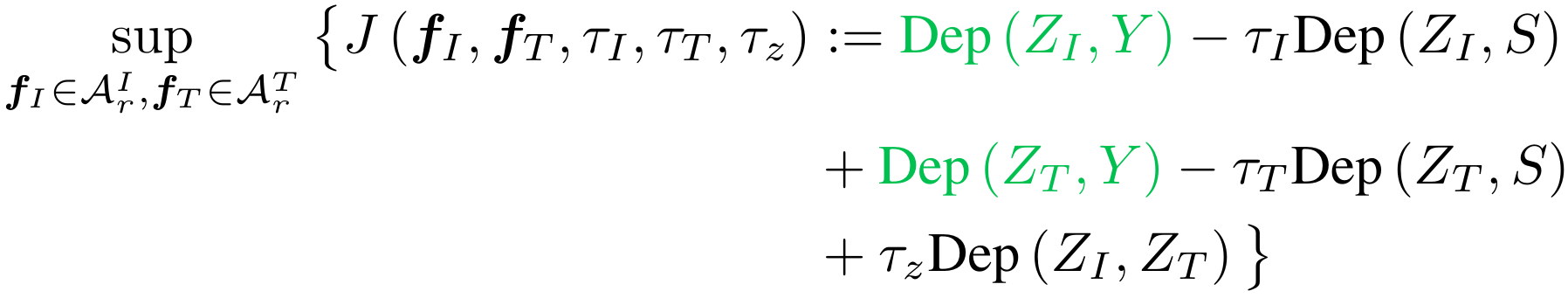
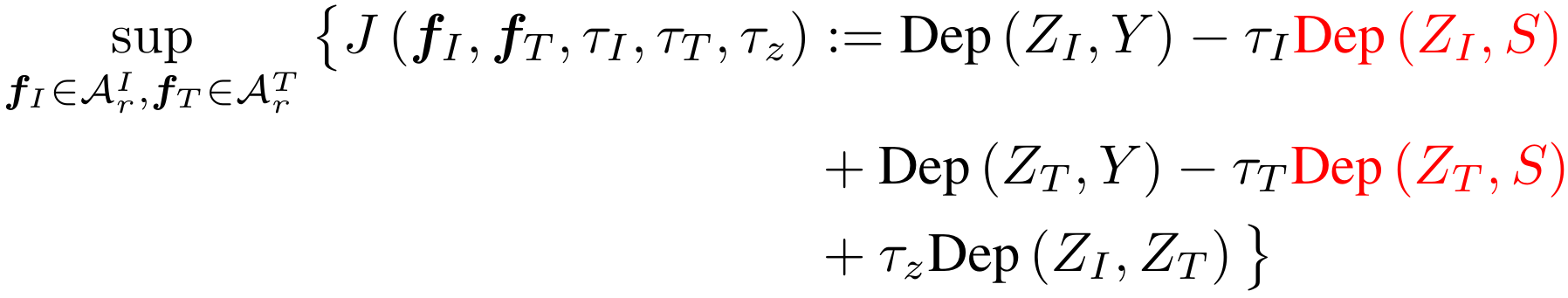
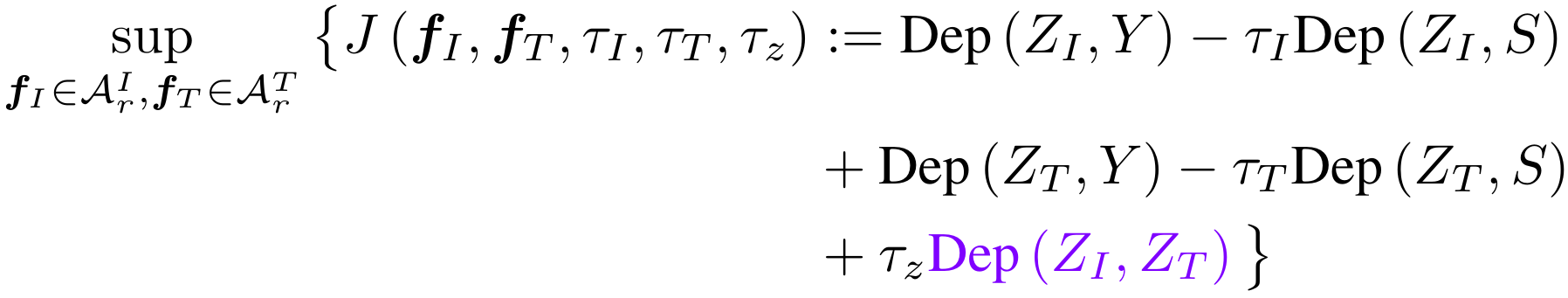
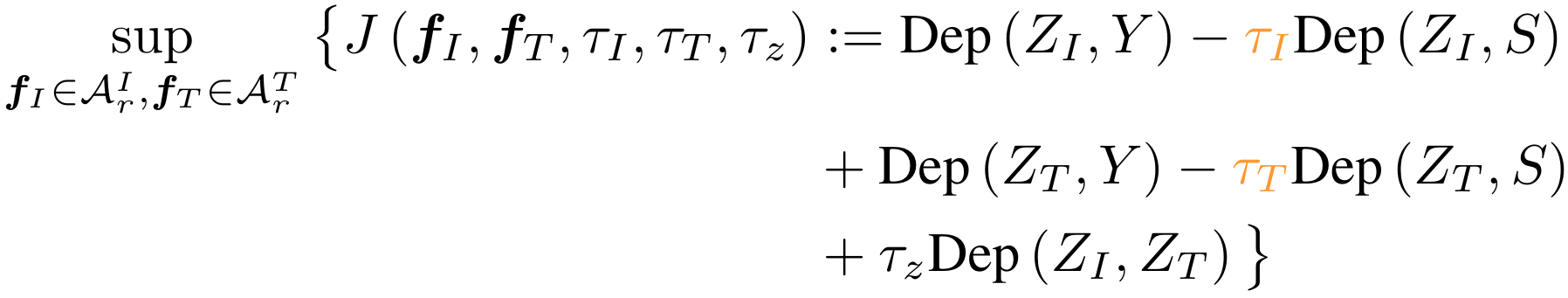
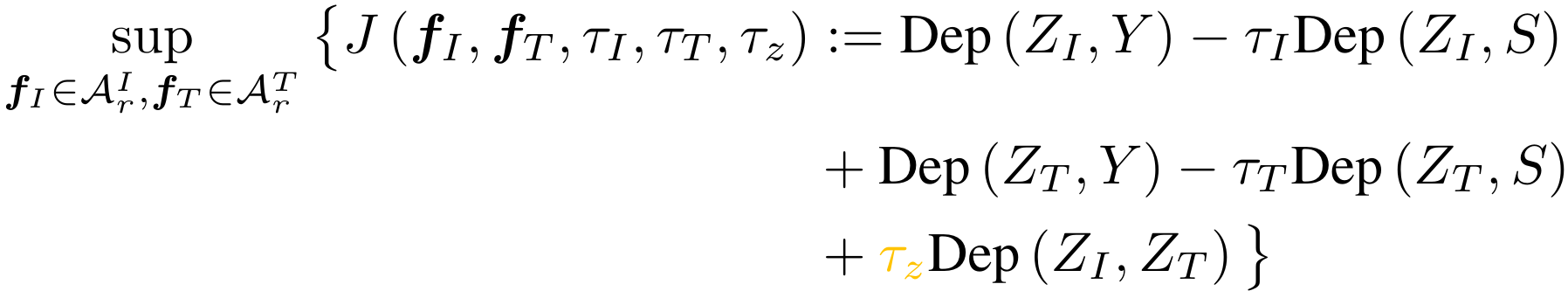
Choice of Dep
Simplified Definition of HSIC
\( \text{Dep}(Z, S) :=\sum_{j=1}^r \sum_{\beta \in \mathcal U_S } \text{Cov}^2\left(Z_j, \beta(S)\right) \)
Empirical Estimation
\( \text{Dep}(f(X), S) := \frac{1}{n^2} \| \bm \Theta \bm K_X \bm H \bm L_S \|^2_F \)
\( \text{Dep}(f(X), S) := \frac{1}{n^2} \| \bm \Theta \bm K_X \bm H \bm L_S \|^2_F \)
Choice of Encoder
- Functions in RKHSs
- Universal Approximation
- Computationally Efficient
Training
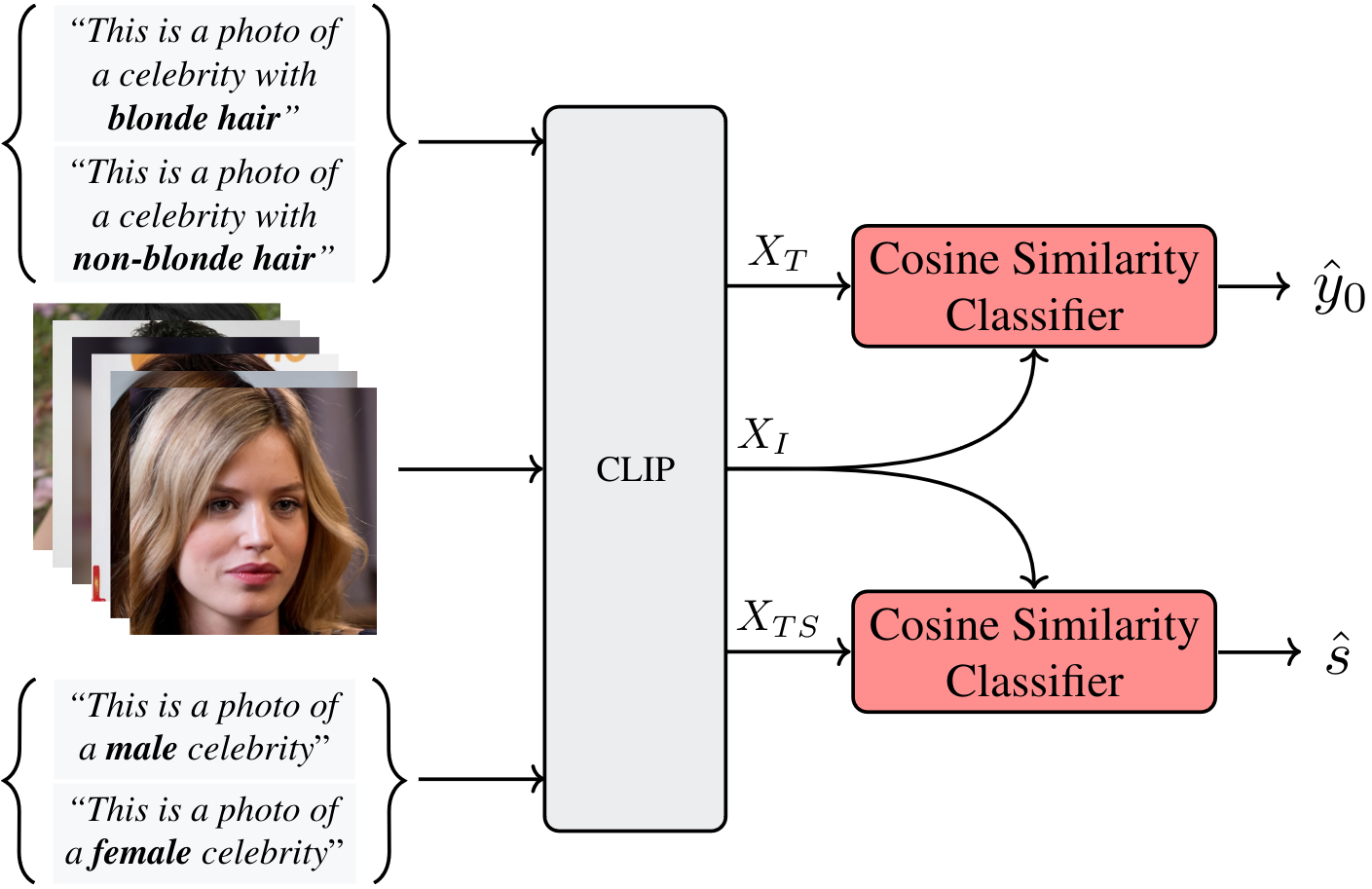
Pseudo-Label Prediction
A Geometric Illustration
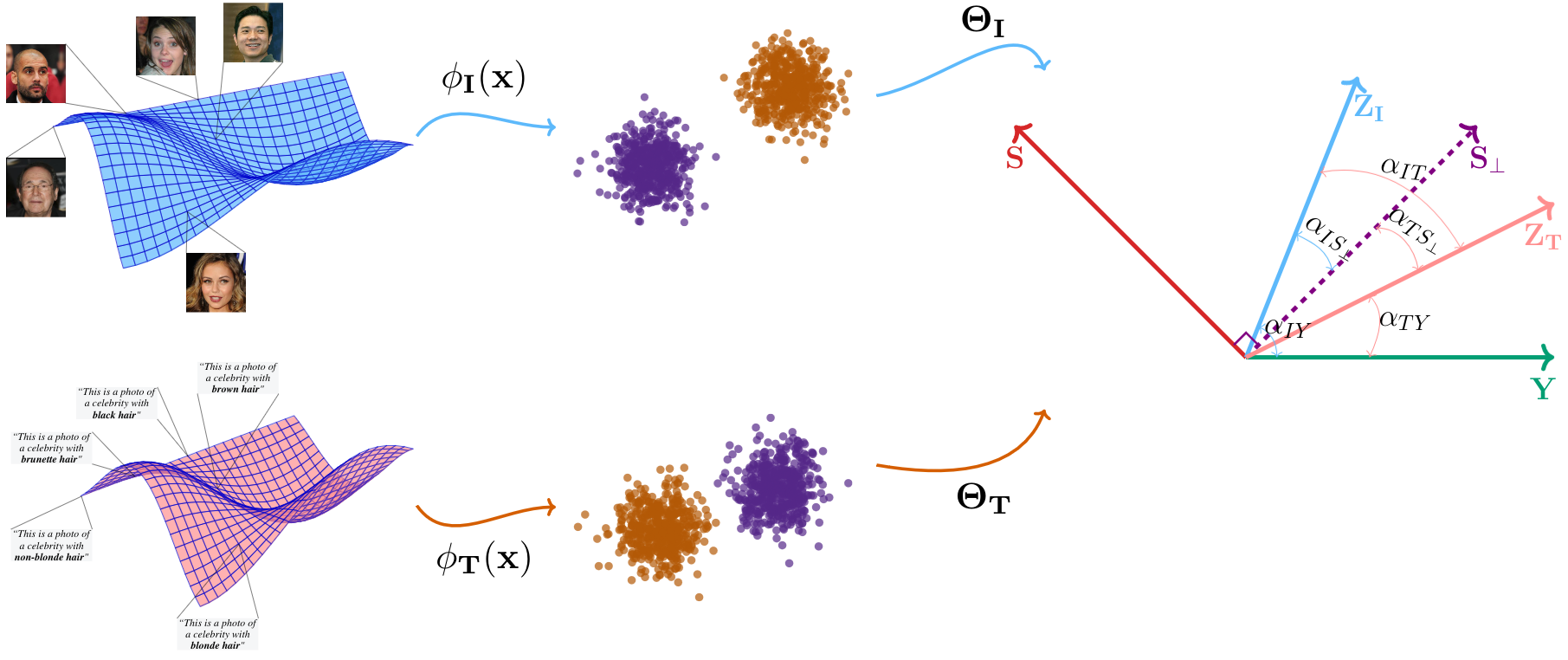
FairerCLIP
Inference Overview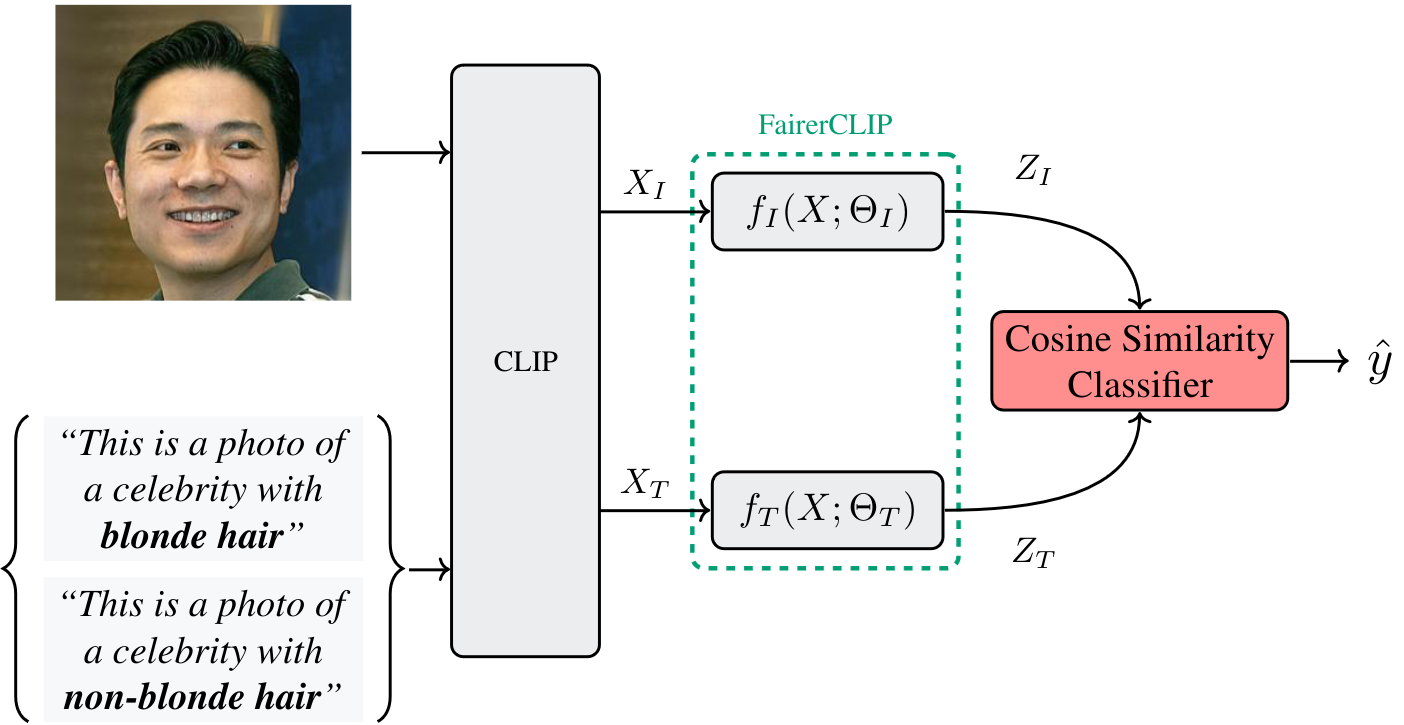
Experimental Results
- Settings
- Mitigating Intrinsic Dependency
- Mitigating Spurious Correlation
Mitigating Intrinsic Dependency
CelebA- Y: High Cheekbone
- S: Gender
Mitigating Spurious Correlation
W/O Labels
W/ Labels
Mitigating Spurious Correlation
CFD
Computational Efficiency of Training
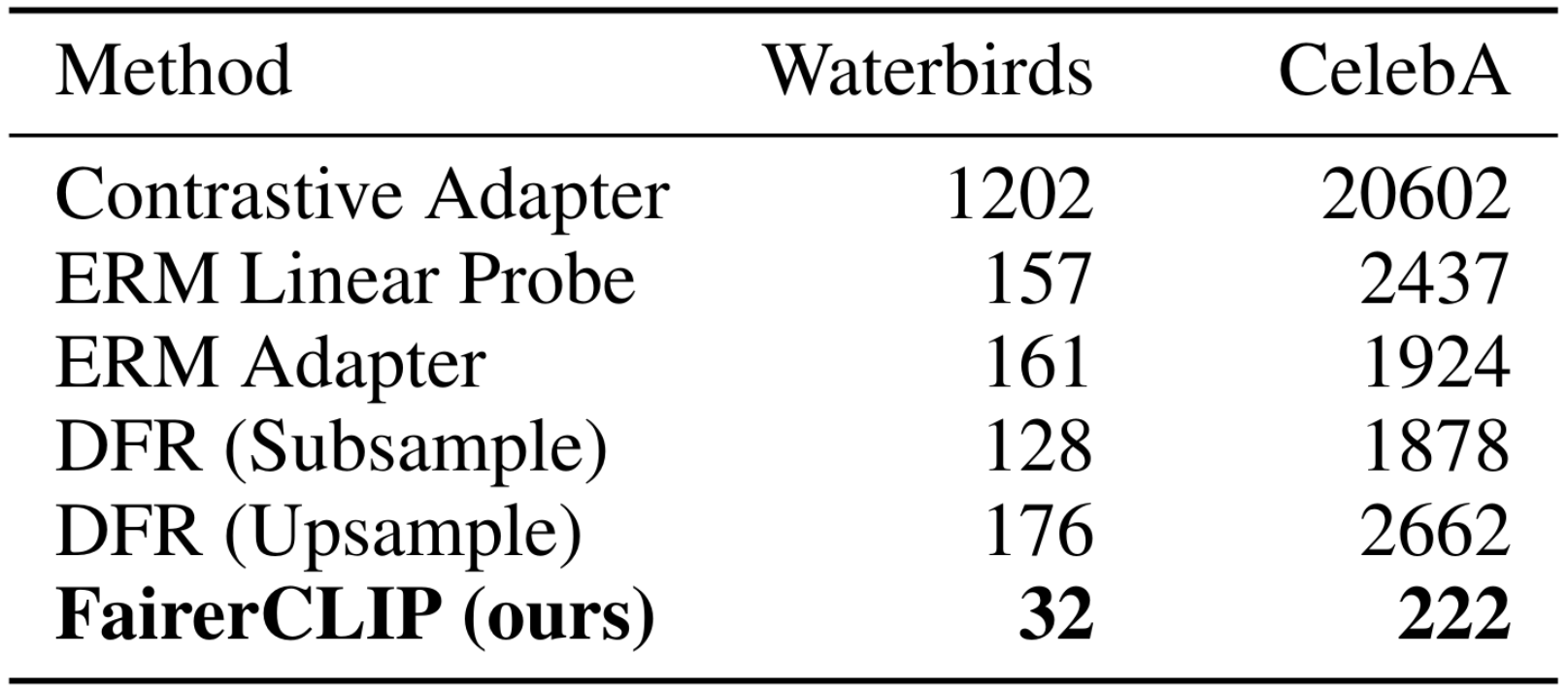
Summary
- Mitigates:
- Spurious Correlation
- Intrinsic Dependency
-
Setting:
- w/ Labels
- w/o Labels
Thank you!