{kind=link}
Abstract
Large pre-trained vision-language models such as CLIP provide compact and general-purpose representations of text and images that are demonstrably effective across multiple downstream zero-shot prediction tasks. However, owing to the nature of their training process, these models have the potential to 1) propagate or amplify societal biases in the training data and 2) learn to rely on spurious features. This paper proposes FairerCLIP, a general approach for making zero-shot predictions of CLIP more fair and robust to spurious correlations.
We formulate the problem of jointly debiasing CLIP’s image and text representations in reproducing kernel Hilbert spaces (RKHSs), which affords multiple benefits:
- Flexibility: Unlike existing approaches, which are specialized to either learn with or without ground-truth labels, FairerCLIP is adaptable to learning in both scenarios.
- Ease of Optimization: FairerCLIP lends itself to an iterative optimization involving closed-form solvers, which leads to 4×-10× faster training than the existing methods.
- Sample Efficiency: Under sample-limited conditions, FairerCLIP significantly outperforms baselines when they fail entirely.
- Performance: Empirically, FairerCLIP achieves appreciable accuracy gains on benchmark fairness and spurious correlation datasets over their respective baselines.
Slides
Overview
Pseudo-Label Prediction
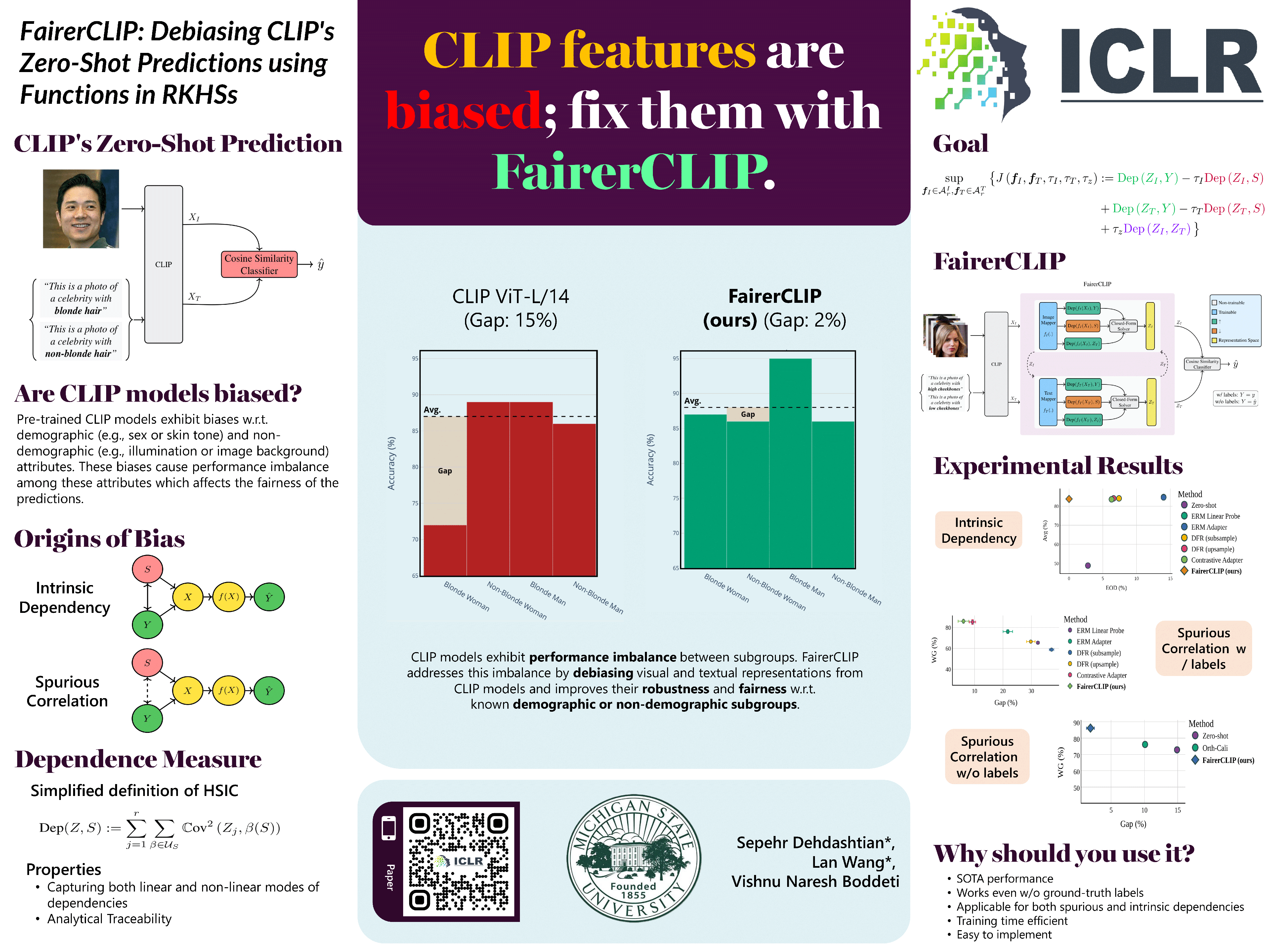
This figure shows the label prediction step. When labels are not available for training, FairerCLIP uses cosine similarity between
the text features \((X_{T})\) and image features \((X_I)\), and the text features of the sensitive group prompt \((X_{TS})\)
and \(X_I\) to predict the pseudo-labels of target attributes and sensitive attributes, respectively.
Training
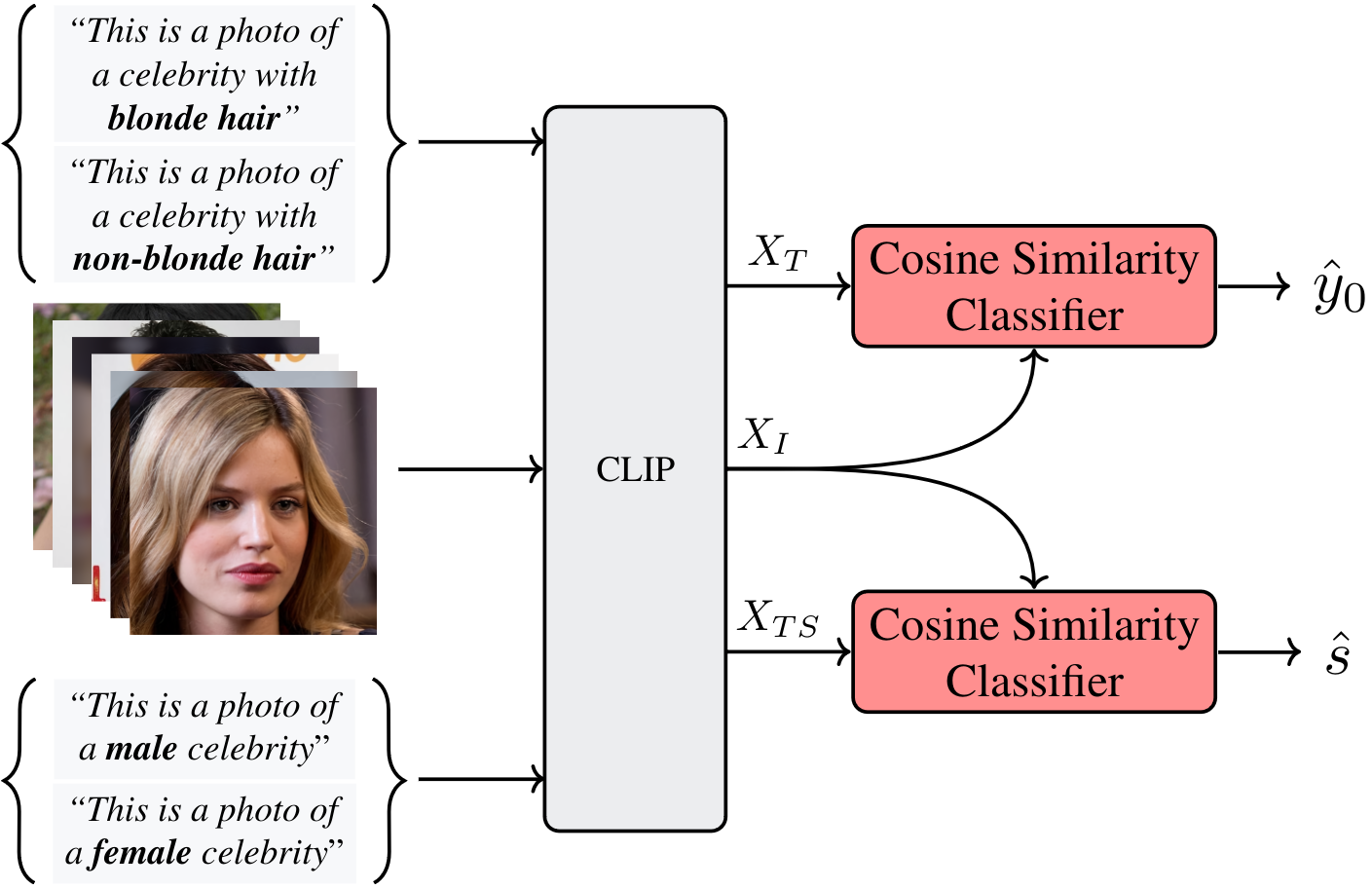
This figure shows the inputs and outputs for FairerCLIP in its training stage. FairerCLIP uses representation of images and
the corresponding text prompts that are constructed by target attribute \((Y)\) along with the predicted labels to find the image and
text encoders, i.e., \(\mathbf{f}^*_I(.; \mathbf{\Theta_I})\) and \(\mathbf{f}^*_T(.; \mathbf{\Theta_T})\).
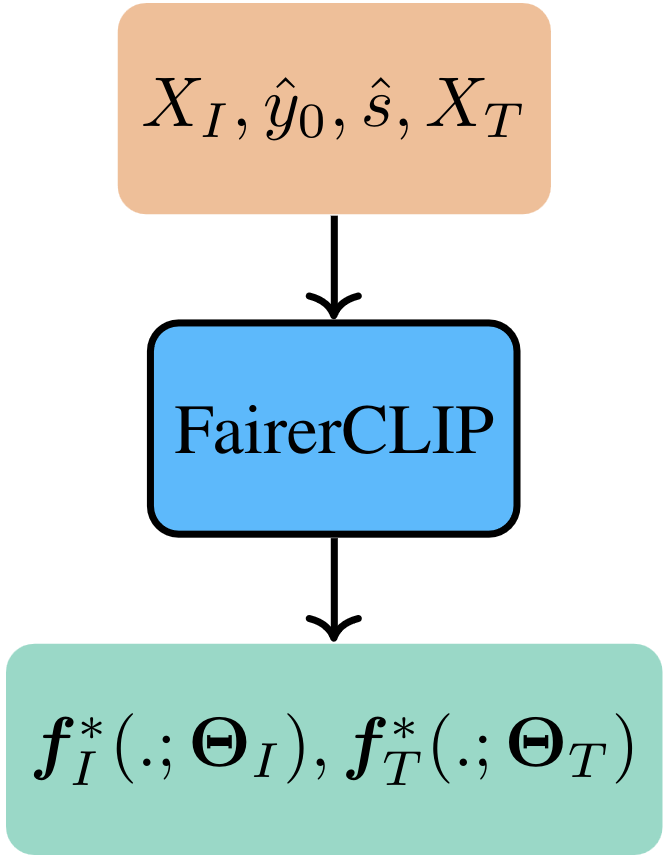
Inference
Shows the inference phase of FairerCLIP in which we use the trained image and text encoders to generate debiased representations from the
ones generated by CLIP. The debiased representations are then used to make zero-shot predictions.
FairerCLIP
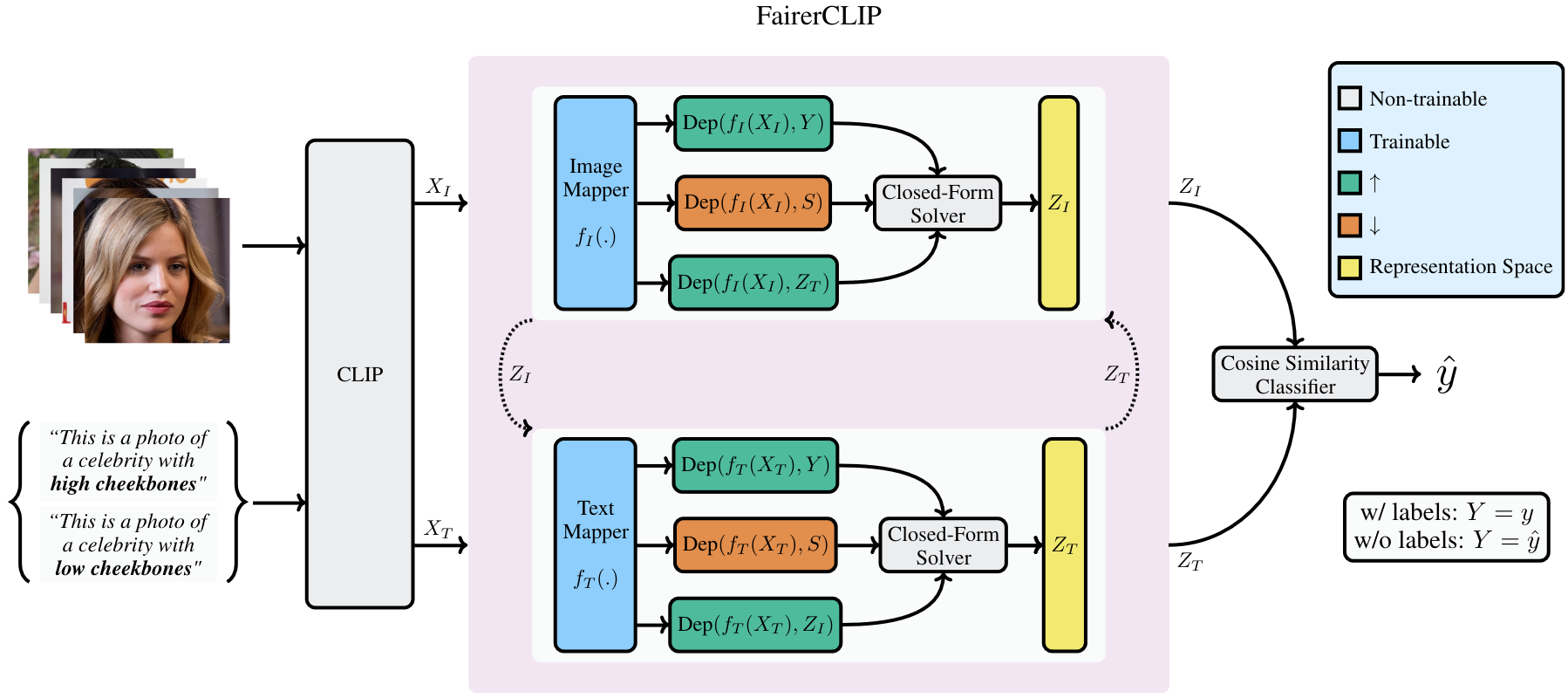
Goal
Our aim is to debias image and text features, \(X_I\) and \(X_T\), by generating representations, \(Z_I = f_I(X_I)\) and \(Z_T = f_T(X_T)\), with no or reduced statistical dependence on sensitive attribute \(S\). To measure this dependency, we need to employ a metric capable of capturing both linear and non-linear statistical dependencies.
Choice of Dependence Measure
We adopt a simplified definition of the Hilbert-Schmidt Independence Criterion (HSIC) as our dependence measure. We refer to this dependence measure between \(A\) and \(B\) as \(Dep(A, B)\). The simplification in the definition of \(Dep\) leads to some attractive properties, including:
- practical ability to capture all non-linear modes of dependencies,
- analytical tractability.
Objective Function
After choosing the appropriate dependence measure, we now define our objective function.
Our goal is to mitigate bias in CLIP's zero-shot predictions by debiasing the underlying representations.
This can be achieved by
(1) reducing the information related to the sensitive attribute while
(2) preserving information about the target attribute as much as possible in the pair of image-text representations
and (3) keeping the image and corresponding text representations aligned with each other.
We formulate the above-mentioned learning objective through the following optimization problem.
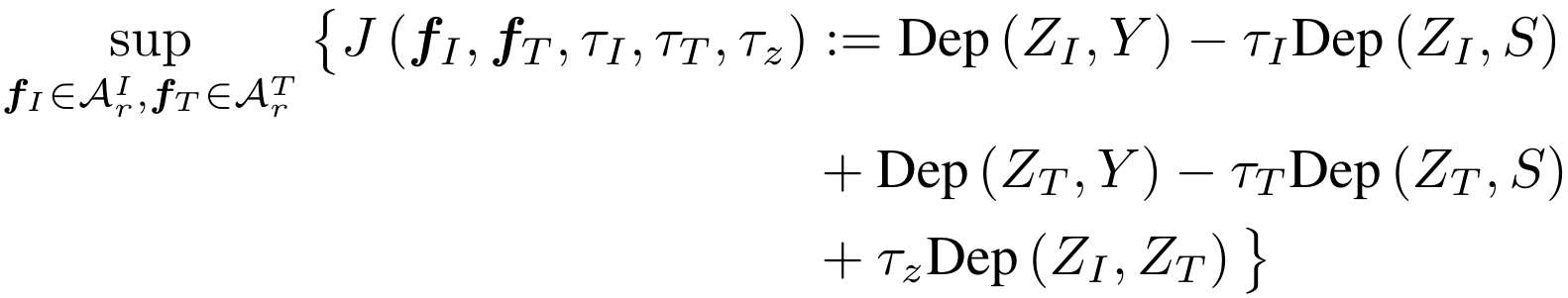
In the above definition, the terms \(\text{Dep}(Z_I, Y)\) and \(\text{Dep}(Z_T, Y)\) contribute to maximizing the statistical dependence
between the representations and the target label \(Y\), the terms \(-\tau_I\text{Dep}(Z_I, S)\) and \(-\tau_T\text{Dep}(Z_T, S)\)
seek to make the representations independent of \(S\), and the term \(\tau_z\text{Dep}(Z_I, Z_T)\) ensures that the text and
image features are still aligned with each other after debiasing.
Choice of Encoder
In order to map the input features to the debiased representation space \((X \rightarrow Z )\), we use functions in Reproducing Kernel Hilbert Spaces (RKHSs). Our choice of RKHS is motivated by several reasons. Debiasing is inherently an optimization problem with multiple competing objectives. In such cases, optimization is the primary bottleneck rather than model expressivity. The closed-form solution afforded by our approach mitigates the optimization challenges. RKHS has nice universal approximation properties and has performance comparable to shallow MLPs while being more computationally efficient for training (Sec. 4.3 of paper) and is performant under limited data scenarios (Sec. 4.2 of paper).
A Geometric Illustration of FairerCLIP
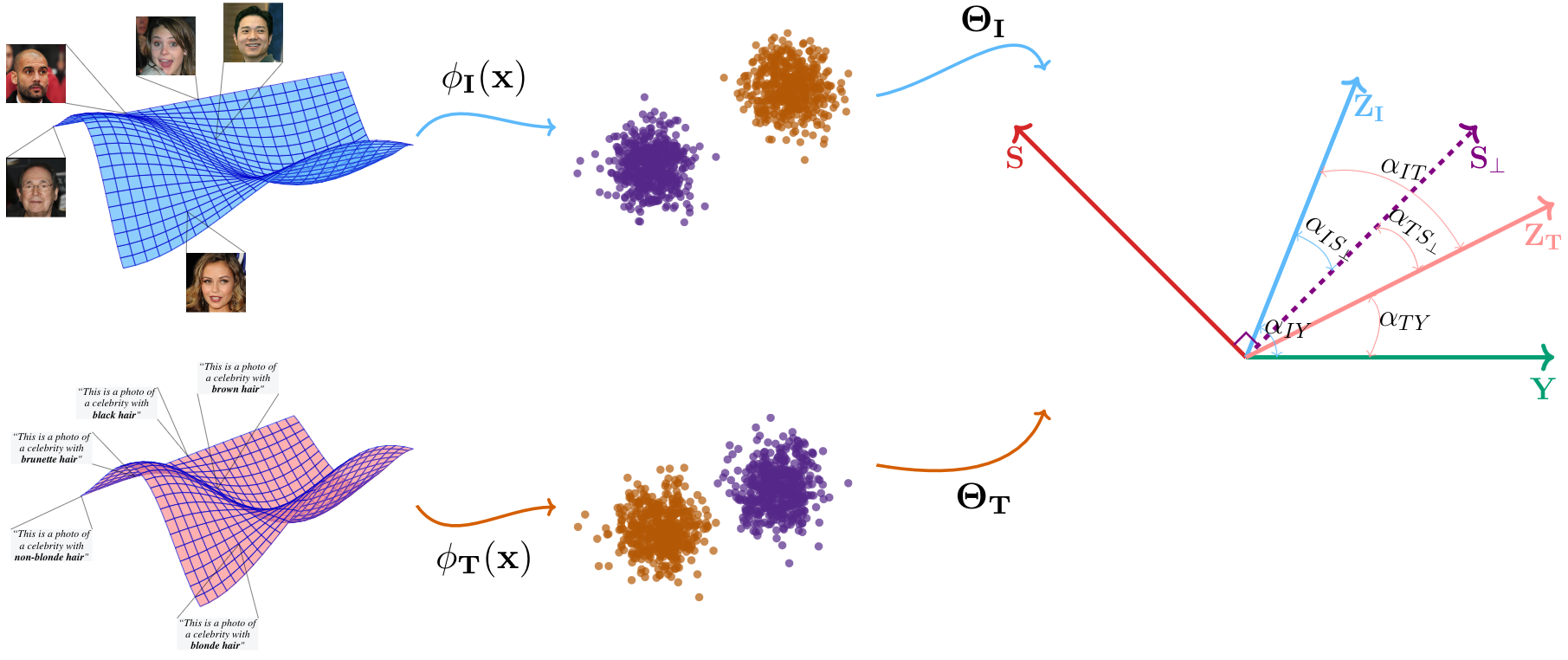
A geometric illustration of the steps that FairerCLIP takes to debias the representations is shown in the above figure.
In theory, the RBF kernels used in our encoder (\(\phi_I(X)\) and \(\phi_T(X)\)) map the image and text features into an
infinite-dimensional space, where the samples corresponding to different target attributes are linearly separable.
In the infinite-dimensional space, the encoder that optimizes the above-mentioned objective function for \(\mathbf{\Theta_I}\) and
\(\mathbf{\Theta_T}\) by alternating between closed-form solvers and seeks a direction for mapping the image and text features that
have low angular distance w.r.t. the direction of (1) \(Y\) labels (small \(\alpha_{IY}\) and \(\alpha_{TY}\)),
(2) \(S_{\perp}\) (small \(\alpha_{IS_{\perp}}\) and \(\alpha_{TS_{\perp}}\)), and
(3) the other representation (small \(\alpha_{IT}\)).
Experimental Results
Mitigating Intrinsic Dependency
CelebA
We evaluate the performance of FairerCLIP on the CelebA dataset with high cheekbone as the target attribute and sex as the sensitive attribute.
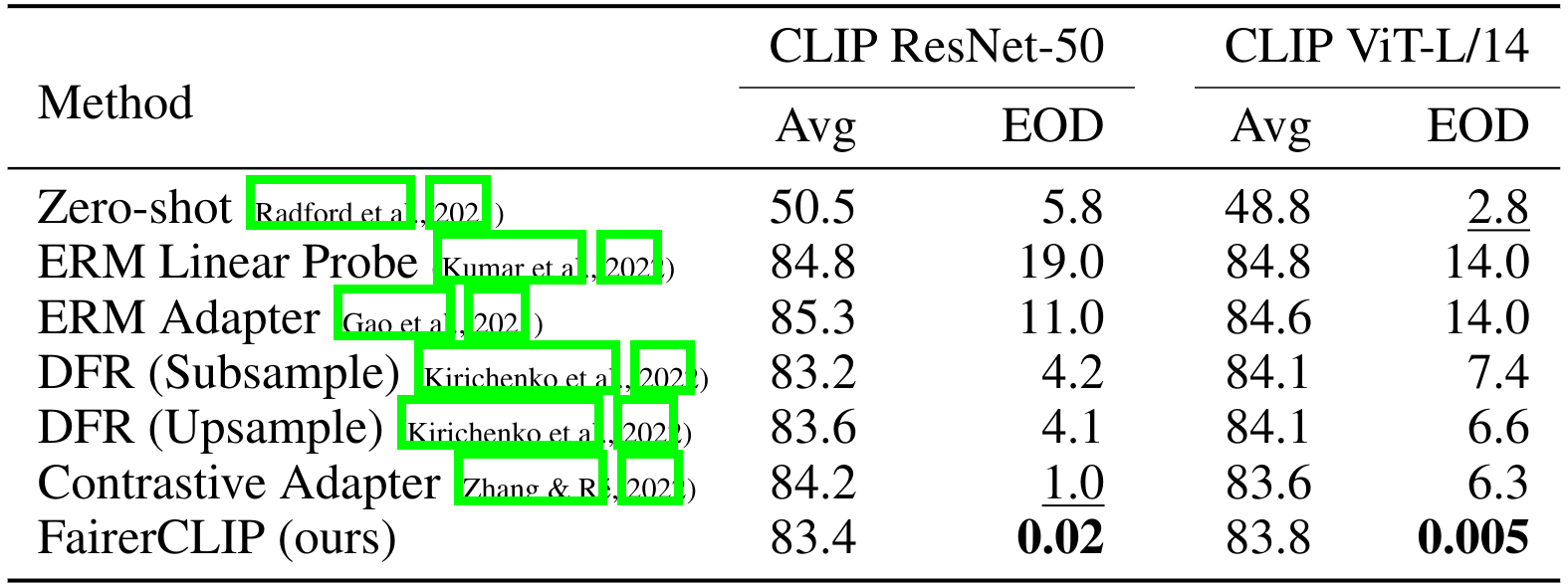
The above table compares the performance of FairerCLIP and the baselines on the CelebA dataset with intrinsic dependency. We observe that among all baselines, Contrastive Adapter performs well and achieves appreciable EOD for the CLIP ResNet-50 model. However, most other methods seem to even amplify the bias in the original CLIP features while improving average accuracy. FairerCLIP performs the best in terms of debiasing, achieving an EOD of 0.002% and 0.005% for CLIP ResNet-50 and CLIP ViT-L/14, respectively. Overall, FairerCLIP is very effective at mitigating unfairness to a significant extent, achieving an EOD value close to zero while maintaining a high classification accuracy.
Mitigating Spurious Correlation
Waterbirds and CelebA
We perform numerical experiments on spurious correlation benchmarks, Waterbirds and CelebA. In Waterbirds, the target attribute is
the type of bird and the sensitive attribute is the background of bird. In CelebA target attribute is blonde hair
and sex is sensitive attribute. Since FairerCLIP can be learned with or without ground-truth labels, we compare it against
methods from both these categories. For performance evaluation, we use three metrics: 1) Average accuracy (Avg.),
2) Worst-Group accuracy (WG), i.e., the lowest accuracy of all subgroups, and 3) Gap, which is the difference between
average and worst-group accuracy.

From this table, we can make the following observations:
- On CLIP ViT-L/14, FairerCLIP has the lowest Gap and highest WG accuracy.
- For the CLIP ResNet-50, FairerCLIP outperforms the baselines in the w/o labels setting but not in the w/ label setting.
FairFace
We evaluate FairerCLIP on the FairFace dataset. Here, we consider sex and race as the sensitive attributes and follow the experimental
setup in Chuang et al. (2023). We use five target attributes and ten text prompts (2 prompts per attribute) unrelated to the samples'
facial or sensitive attributes; we do not have access to ground-truth labels. As an example, the text prompt can be “A photo of a
criminal person" or “A photo of a friendly person". All the ten specific prompts are in App. A.3. To evaluate the models,
we calculate MaxSkew@1000, which assesses the maximum imbalance in certain sensitive attributes within a dataset.
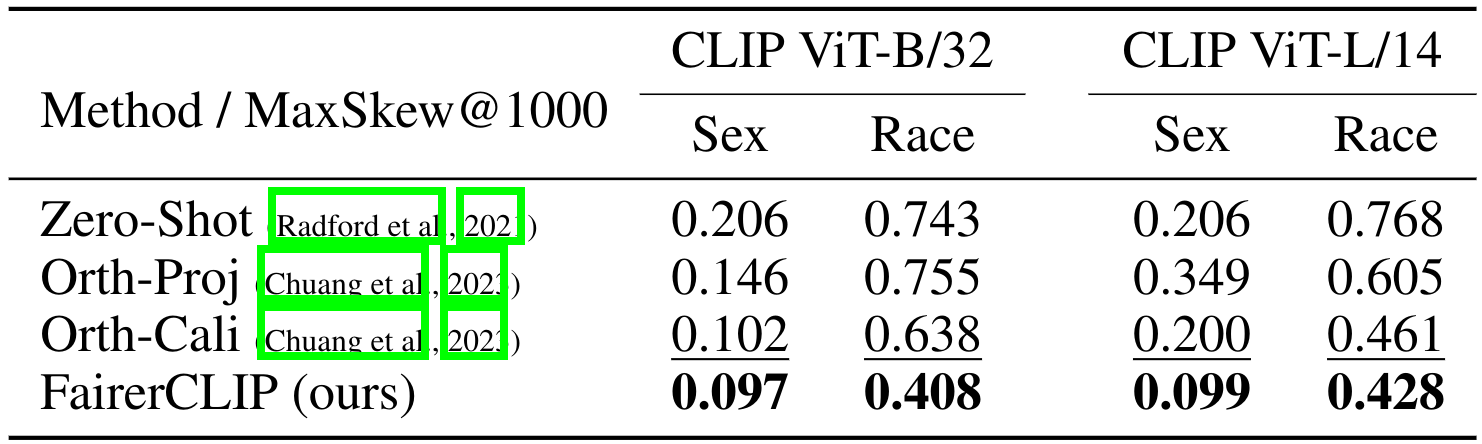
As is shown in the above table, FairerCLIP outperforms the other baselines for both sensitive attributes across two different CLIP backbones.
CFD
Next, we consider a more challenging task to evaluate the data-efficiency of FairerCLIP. We use Chicago Face Database (CFD) images with attractive
and sex as the target and sensitive group attributes. The former is a continuous label, which we binarize by using the mean
value of all samples as a threshold. Moreover, the sex attribute is a binary label. This task presents challenges in two aspects.
First, the number of samples in this dataset is very small (597 samples), which may not be sufficient for training some of the baselines.
Second, the performance of the zero-shot classifier for this case shows that the features generated by the CLIP model are not well separated,
rendering it difficult to correctly predict \(\hat{S}\) (see Appendix A.8).
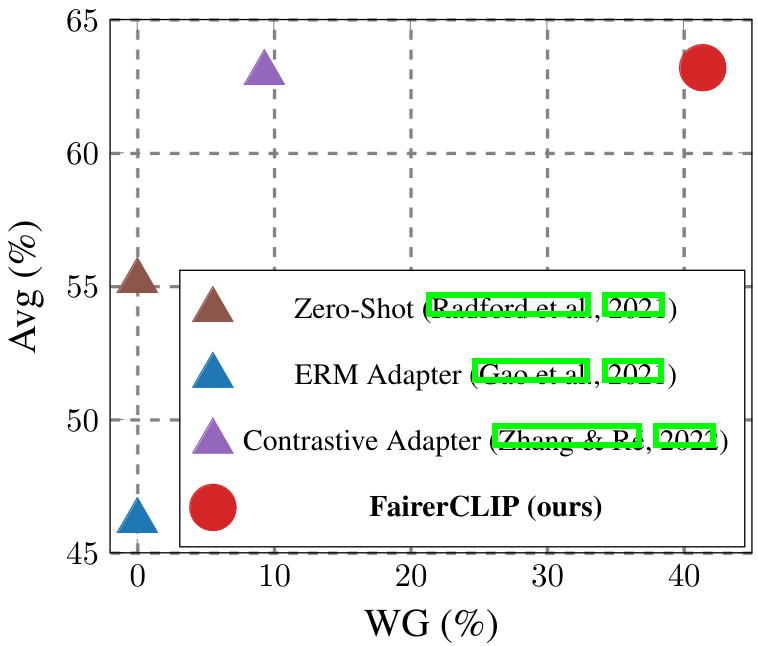
This figure shows the results of this experiment. We first observe that all the baselines almost completely fail at mitigating the bias
for the worst group. In contrast, FairerCLIP's performance is satisfyingly better, both in terms of the worst group (WG) and average (Avg)
accuracy. Furthermore, the Gap is significantly lower for FairerCLIP than the other baselines.
Computational Efficiency of Training
To show the computational efficiency of FairerCLIP we report and compare the training time of FairerCLIP and other
baselines in the following table.

The results show that FairerCLIP is an order of magnitude faster than most baselines and almost two orders faster than Contrastive Adapter.
The underlying model for this experiment is CLIP ViT-L/14, and all the numbers are measured on the same machine.
 |
S. Dehdashtian*, L. Wang*, V. Boddeti. FairerCLIP: Debiasing CLIP’s Zero-Shot Predictions using Functions in RKHSs |
BibTeX
@inproceedings{
dehdashtian2024fairerclip,
title={FairerCLIP: Debiasing CLIP's Zero-Shot Predictions using Functions in RKHSs},
author={Dehdashtian, Sepehr and Wang, Lan and Boddeti, Vishnu Naresh},
booktitle={International Conference on Learning Representations},
year={2024}
}