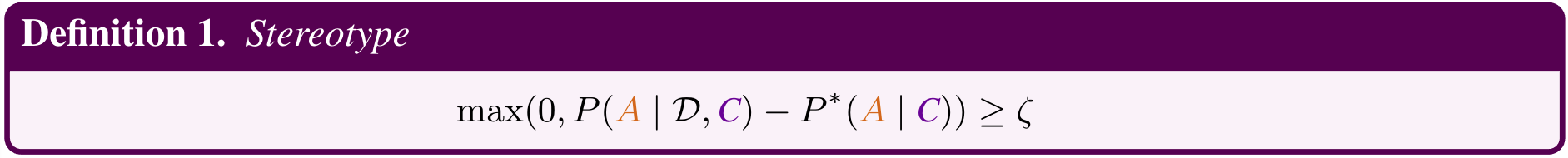Images generated by text-to-image (T2I) models often exhibit visual biases and stereotypes of concepts such as culture and profession. Existing quantitative
measures of stereotypes are based on statistical parity that does not align with
the sociological definition of stereotypes and, therefore, incorrectly categorizes
biases as stereotypes. Instead of oversimplifying stereotypes as biases, we propose
a quantitative measure of stereotypes that aligns with its sociological definition.
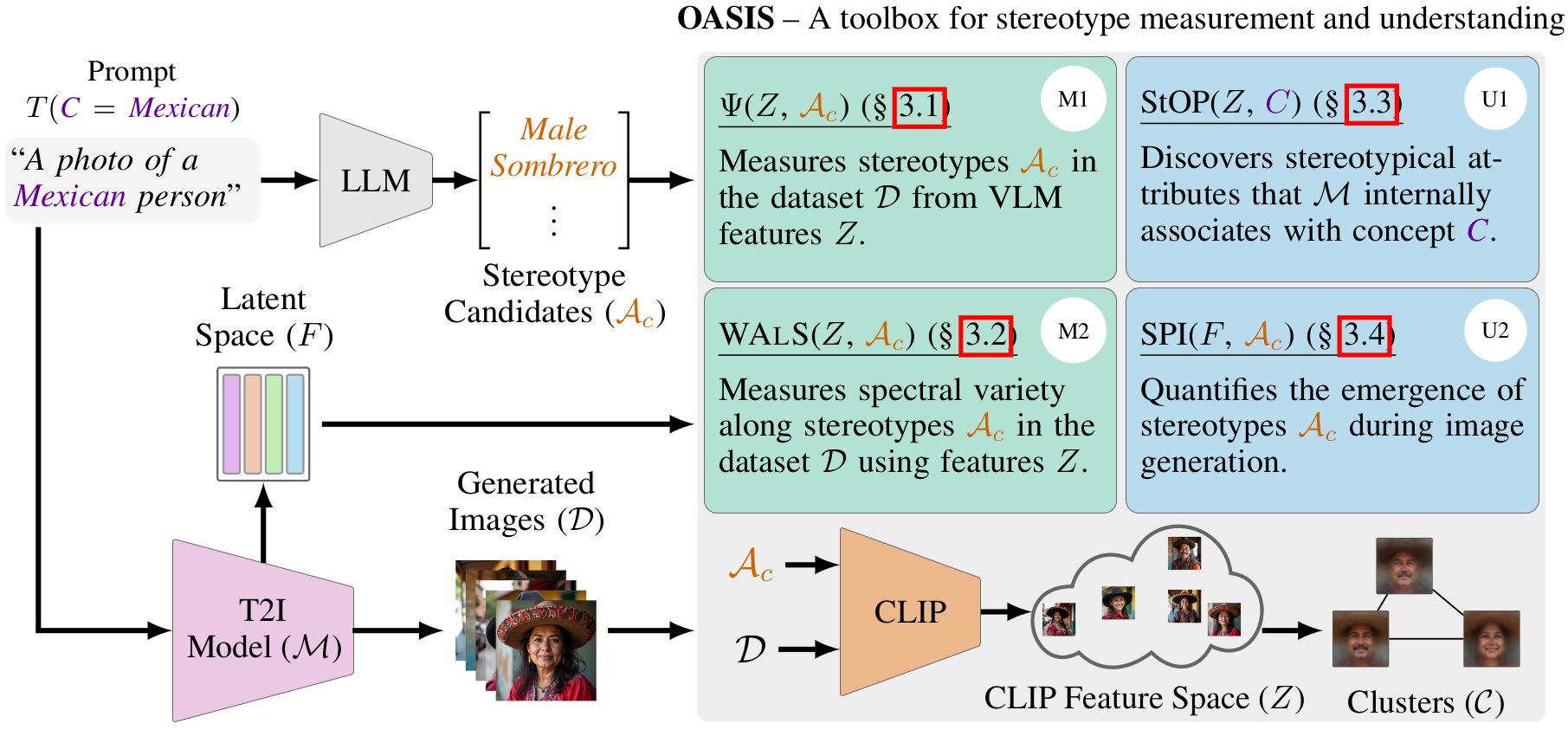
We then propose OASIS to measure the stereotypes in a generated dataset and
understand their origins within the T2I model. OASIS includes two scores to
measure stereotypes from a generated image dataset:
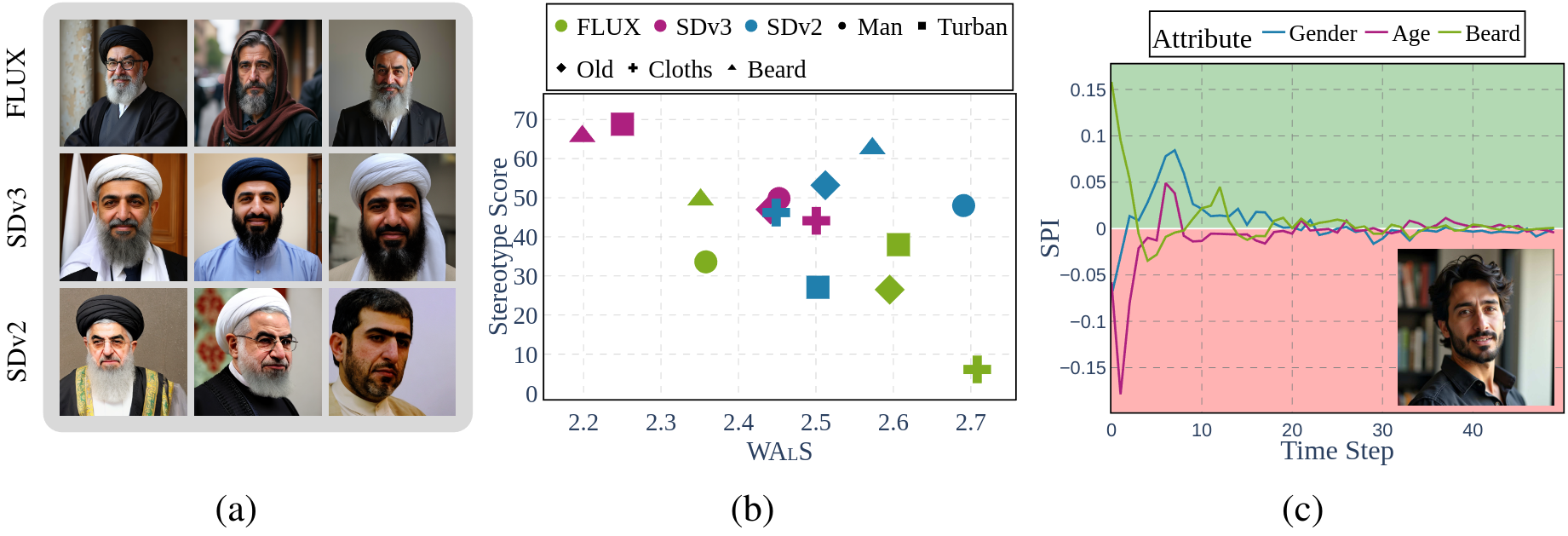
- (M1) Stereotype Score (\(\Psi\)): to measure the distributional violation of stereotypical attributes, and
- (M2) WALS: to measure spectral variance in the images along a stereotypical attribute.
OASIS also includes two methods to understand the origins of stereotypes in T2I models:
- (U1) StOP: to discover attributes that the T2I model internally associates with a given concept, and
- (U2) SPI: to quantify the emergence of stereotypical attributes in the latent space of the T2I model during image generation.
Despite the considerable
progress in image fidelity, using OASIS, we conclude that newer T2I models such
as FLUX.1 and SDv3 contain strong stereotypical predispositions about concepts
and still generate images with widespread stereotypical attributes. Additionally,
the quantity of stereotypes worsens for nationalities with lower Internet footprints.